
FEX 2309 Tagged!
Last month we hinted that we didn’t get all optimizations in that we wanted. There’s more of that this month but we have also had an entire month to push optimizations in. This month was a whirlwind of optimizations improving performance all over the place because of one feature that landed; Instruction Count continous integration! Let’s dive in to what this is.
Instruction Count CI
This is a major feature that we added last month that doesn’t directly affect users but is such a huge quality of life improvement to our developers that we need to discuss what it is. At its core, InstCountCI is a database (Actually JSON) of x86 instructions that FEX-Emu supports and shows how that instruction gets converted to Arm64 instructions. This is in textual format for easily reading these instruction implementations and updating quickly when the implementation changes. This has had a profound effect on our developers where they can’t help but look at poor instruction implementations and finding ways to optimize them.
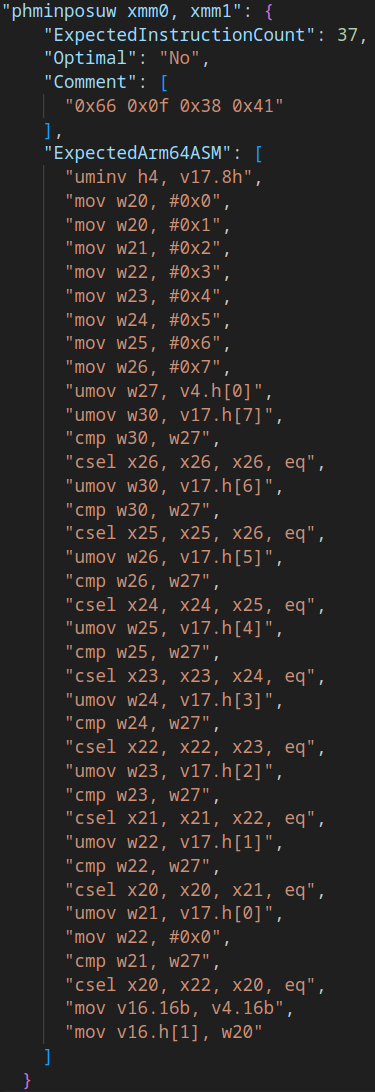
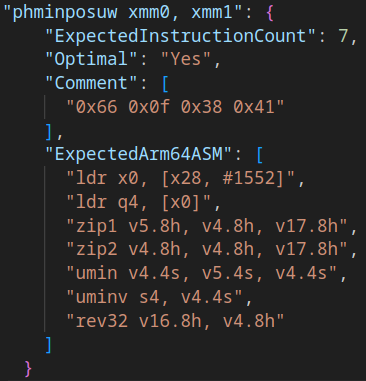
As you can see in the example, one very complex instruction that was not optimal before has now translated in to something much more reasonable. So far this has nerdsniped at least half a dozen developers in to finding more optimal implementations of these instruction translations!
Some design considerations of this must be understood when looking at FEX’s instruction implementations although. The most important thing to remember is that these implementations are looking at the instruction in a vacuum. These are translated as only single instruction entities, so any sort of multi-instruction optimization is not going to be visible in this CI system. Additionally this isn’t getting run on hardware in our CI, so implementations that are close on instruction count may have wildly different performance characteristics depending on the hardware. So while it is a good guide for getting eyes on the assembly, there still needs to be some knowledge as for what the translation is doing to ensure it’s both fast and correct. Read more about how InstCountCI works on our Wiki here
This CI system was used heavily this last month for what our next topic is.
Optimization Extravaganza!
With InstCountCI in place, we can now quantify optimizations going in to the FEX CPU JIT without accidentally compromising performance of other instructions. With this in-place we have had an absolute ton of CPU optimizations land in our JIT, enough that if we went through them all it would take longer than all of previous progress reports!
Instead of going through each individual change, let’s just discuss the main optimizations that have landed. The bulk of optimizations has been making sure the translation between SSE instructions to Arm64’s ASIMD instructions is more optimal. This is because reasoning about vector optimizations is easier in this instance, and also because games more heavily abuse vector instructions than regular desktop applications. There were other optimizations like some flag generation instructions becoming more optimal and eliminating redundant move instructions as well!
Let’s take a look at the bytemark results.
There’s some surprising uplift in numbers here! Even more so since bytemark shouldn’t heavily utilize SSE instructions so this is more just coming from general optimizations that occured. Let’s take a look at another benchmark for fun.
Whoa, that is a surprising uplift in one month! Geekbench actually has some benchmarks that use vector operations so they can get improvements more improvements than expected. We should expect even more performance once we start optimizing more non-vector instruction translations!
As for gaming benchmarks, we’re not going to do some in this blog post, but we have been told that due to various optimizations this month that Portal performance has gained 30% and Oblivion has 50%. Big improvements towards making games feel better when playing them. Main concern here is that the Adreno 690 in our Lenovo X13s test systems are actually quite unstable during testing, so finding suitable games that are CPU bound without crashing the kernel driver is surprisingly difficult. Most of the lighter games that don’t crash the MSM kernel driver are already running at hundreds of FPS anyway so it isn’t interesting.
A fun quirk of optimizing vector operations this month, we have finally landed our first optimizations that use ARM’s SVE instruction set when operating at 128-bit width. Turns out there are a few optimizations that can be done here aside from implementing AVX with the 256-bit version! I’m sure we will see more of these as we continue optimizing.
Remove most implicit sized IR operations
Continuing from the last topic, this is one of the main changes that allows us to start working on non-vector instruction optimizations. FEX’s IR around general purpose ALU operations has a history of using implicit sized IR operations. This means we would check the size of the incoming data sources and make an assumption for what the operating size of the whole thing should be. While this worked, it has been an absolute thorn in our side for years at this point. Any time we would make a seemingly innocuous change it would subtly change the behaviour of some IR operations as a new size propagates through the stack. Now that all of these operations explicitly state their operating size at generation time there is less room for error.
This follows with how our vector operations worked, where all of these were explicitly sized from the start and has had significantly less issues over time.
With this change in place we can start optimizing general purpose ALU operations with less worry about breaking the world.
Mingw work
Some more work this month towards getting WINE WOW64 support wired up. Adding a toolchain file to help facilitate cross compiling, stop saving and restoring the x18 platform register and various other things. While full support isn’t yet merged, there’s a lot of preliminary work landing so we can support this. While this work is very early, it is already showing significant performance improvements for Windows native games. A game like Bioshock Infinite is already running faster than FEX emulating x86 WINE fully! Look forward to future improvements and integrations as this gets wired up!
Video game showcase
See the 2309 Release Notes or the detailed change log in Github.